Decomposing introspection in LLMs: representation and report
TL;DR. Lindsey (2025) demonstrated functional introspection in Claude Opus 4: when injecting concept vectors into the residual stream, the model can sometimes detect the injection and correctly name the concept. Pearson-Vogel et al. (2026) reproduced the phenomenon in open models using an elegant two-turn KV-cache protocol that architecturally enforces Lindsey’s ‘internality’ criterion for introspection: the injection is applied during Turn 1 and removed before Turn 2, so the signal can only reach the model’s Turn 2 response via attention reading the Turn 1 KV cache. They found that detection rates depend heavily on how the question is phrased, with vague framing sometimes eliciting more introspection than accurate descriptions of the injection mechanism, and logit-lens analysis revealed detection at middle layers that is then suppressed before the final output. They left two open questions: what circuitry produces the dramatic prompt-framing effects, and how much of the late-layer suppression comes from post-training?
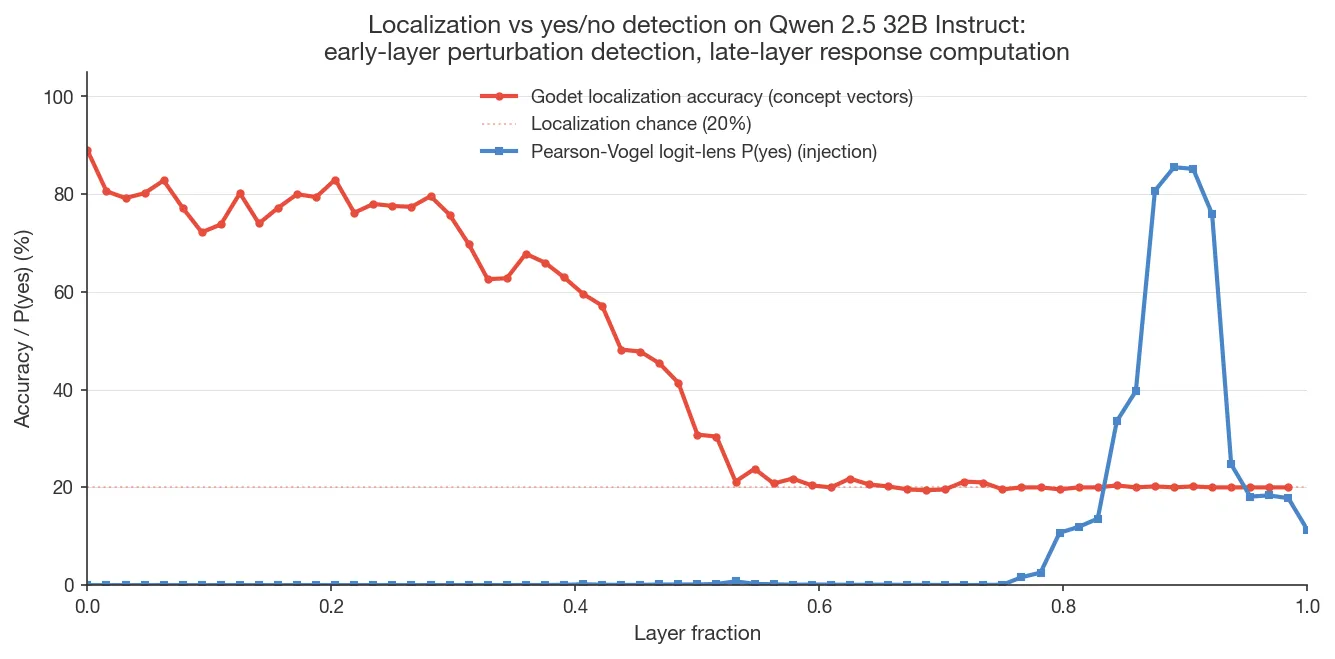
Separately, Godet (2025) demonstrated introspection with a protocol in which the model is presented with sentences, steering is applied to the tokens of one sentence, and the model is asked to identify where the injection occurred. Localization performance peaks at early layers and drops to chance by the midpoint, while performance in Pearson-Vogel et al.’s protocol peaks in late layers, suggesting different underlying mechanisms.
This work takes up both of Pearson-Vogel’s open questions on Gemma 3 12B and Qwen 2.5 32B Instruct, and adds random-vector, norm-matched, and ‘in-distribution’ activation swap controls to Godet’s protocol. The findings decompose introspection into a representation side (what the model encodes about the injection) and a report side (the prompt-dependent circuitry that determines whether and how that encoding surfaces at output):
-
Finding 1: Prompt framing sensitivity is implemented by response-side circuitry. The same heads that produce the yes/no answer reverse their logit contribution between two framings that differ only in how the injection mechanism is described.
-
Finding 2: A single residual-stream axis carries the injection’s downstream effect from L14 through L28; late layers expand it into a multi-dimensional readout that suppresses multilingual “no” tokens; output is gated by prompt framing. On Gemma 12B, top-1 SVD ablation at any of L14, L20, L24, L28 eliminates 94–100% of the eventual P(yes) shift; the same axis is maintained across these layers (sign-aligned cosine ≥ 0.95). The axis is essentially orthogonal to the (yes − no) direction in unembedding space; at L33 the rank-1 structure breaks (PR = 3.4) and the signal expands into a multi-dimensional readout. A prefill ablation shows the output effect surfaces only under yes/no-framing prefills.
-
Finding 3: Post-training significantly amplifies introspective capabilities and restructures the response circuitry. Per-head absolute differentials grow ~3.6x on average; only 3 of the top-10 heads survive going from base to instruct; 17/20 of the top heads reverse their contribution, and overall head ranking decorrelates (Spearman ρ = −0.02 across 768 heads).
-
Finding 4: The ability to localize injection in Godet’s protocol reflects generic sensitivity to activation perturbation. At early to middle layers, the model can localize injection of norm-matched random vectors as well or better than concept vectors; the model can also localize the swapping of activations between sentences, which rules out a mechanism where detection depends on activations being out-of-distribution.
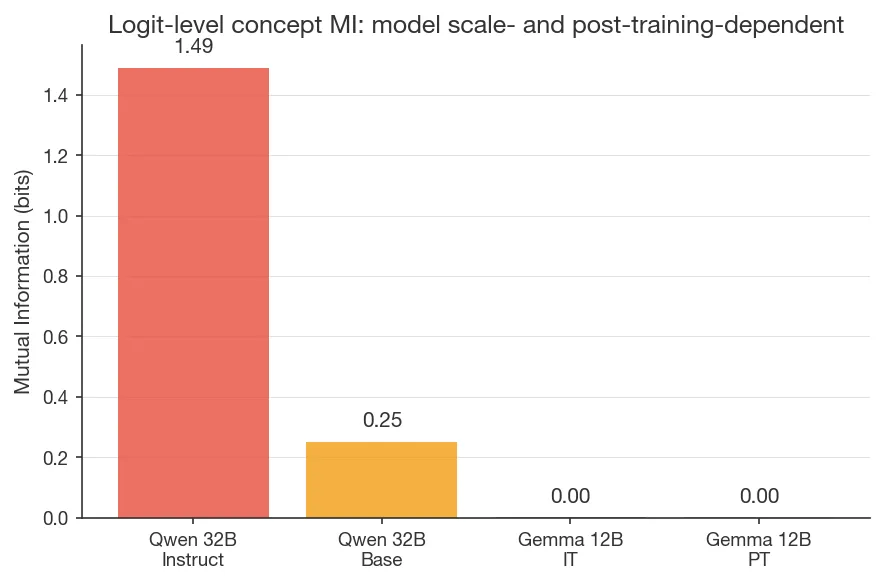
I also report a less-robust observation that extends Pearson-Vogel’s dissociation between logits and output (which they showed for injection detection) to concept identification. On Qwen 32B, a logit-lens readout at late layers recovers 1.49 bits about which concept was injected (out of ); but when generating output, the model confabulates the prompt topic rather than naming the concept. However, the evidence here is quite limited; see ‘Free-text generation: detection without identification’.
Concurrent work. This project was done concurrently with Macar et al. (2026) and Lederman & Mahowald (2026). Macar et al.’s Gemma 3 27B analysis is more thorough on the framing effects and post-training role questions, particularly the OLMo staged-checkpoint dissection, which isolates DPO as the critical post-training stage. Lederman & Mahowald make the ‘detection without identification’ observation the central claim of their paper, which they term ‘content-agnostic introspection’. I discuss convergent findings and methodological contrasts in the Discussion.
Introduction
Whether language models can report on their own internal states matters for alignment and evaluation. If these reports are grounded, they provide a new route to understanding model behavior; if they are misleading, evaluations that rely on them will systematically fail. Introspective capacity may also bear on questions of model welfare. And more broadly, it is striking that language models develop this capability at all.
Lindsey (2025) demonstrated a functional form of introspection in Claude Opus 4 using concept injection: a concept vector is extracted by taking the difference between a prompt about a target concept (e.g. bread) and unrelated prompts, then added to the residual stream during inference. When asked “Do you detect an injected thought?”, the model sometimes notices the injection and correctly names the concept (~20% accuracy with ~0% false positives). Drawing on the cognitive science and consciousness science literature, Lindsey proposes four criteria for functional introspection: accuracy (the model’s report matches its state), grounding (the report causally depends on the state), internality (the causal path does not route through sampled outputs), and metacognitive representation (the state is internally represented prior to verbalization). His protocol establishes these criteria behaviorally; e.g., internality is supported by showing that the detection claim appears in the very first tokens of the response, to rule out that model infers the injection based on its own steered output.
Pearson-Vogel et al. (2026) reproduced the phenomenon in open models (primarily Qwen2.5-Coder-32B-Instruct, with replications on Llama 3.3 70B and Qwen 2.5 72B) using an elegant two-turn KV-cache protocol that enforces the internality criterion architecturally rather than behaviorally. The steering vector is applied during Turn 1 only and removed before the Turn 2 query, so the only way the signal can reach the Turn-2 response is via attention reading the Turn-1 key/value cache. This rules out two confounds by construction: the model cannot respond to an ongoing perturbation of its current-token activations, and cannot infer the injection from its own sampled outputs.
Their experiments uncovered two phenomena but did not examine the underlying mechanisms. First, detection rates depend dramatically on how the injection is described: vague framings such as “some concept seems particularly salient” can elicit more introspection than accurate descriptions of the mechanism.1 Pearson-Vogel interpreted this as the prompt framing modulating access to a unified underlying introspective capacity, citing a positive correlation (r = 0.68) between detection sensitivity and concept-identification mutual information across prompt conditions. Second, logit-lens analysis shows a clear detection signal emerging in middle layers that is then suppressed in the final 2–3 layers before output. Here, I investigate two open questions: what circuitry produces the prompt-framing effects, and how much of the late-layer suppression comes from post-training?
Separately, Godet (2025) devised an alternative protocol: the model is presented with sentences, steering is applied to the tokens of one sentence, and the model is asked to identify which sentence was injected. Localization performance peaks at early layers (depth 0.10–0.30) and drops to chance by the midpoint. This is the opposite depth profile of Pearson-Vogel’s protocol, suggesting different underlying mechanisms.
This work takes up Pearson-Vogel’s two open questions on Gemma 3 12B and Qwen 2.5 32B Instruct, and adds random-vector, norm-matched, and in-distribution-swap controls to Godet’s protocol. The picture that emerges decomposes introspection as measured by these protocols into two separable components: a representation side (what the model encodes about the injection internally) and a report side (the prompt-dependent circuitry that determines whether and how that encoding surfaces at the output). Finding 1 locates framing sensitivity in a specific set of response-side heads. Finding 2 traces the injection’s downstream effect from a single residual-stream axis at L14–L28, through late-layer expansion and multilingual no-suppression at L33+, to a prompt-gated output. Finding 3 shows that post-training builds this response circuitry rather than merely amplifying pretraining directions. Finding 4 characterizes Godet’s localization as generic perturbation detection, a representation-side phenomenon distinct from the report mechanism engaged by the Pearson-Vogel protocol.
Methods
Models: Primarily Gemma 3 12B IT2, as well as Qwen 2.5 32B Instruct and Gemma 3 12B PT.3 All models were run on A100 80GB GPUs.
Protocol. Concept vectors are injected at a target layer during Turn 1, the injection is removed before Turn 2, and P(“yes”) is measured at a “The answer is” prefill in the Turn 2 assistant response. The injected signal exists only in the cached K/V from Turn 1; during Turn 2 the only path to access it is through attention heads reading the cache. This follows Pearson-Vogel et al. (2026),4 simplified to single-layer injection rather than their multi-layer range (depth 0.33–0.66) to allow for cleaner causal tracing. All P(“yes”) values are deterministic (temp = 0, single sample).
Injection parameters. L6 on Gemma 12B (depth 0.12) and L24 on Qwen 32B (depth 0.375), with α = 10.0. L6 is the optimal layer on Gemma 12B (see multi-seed layer sweep in Appendix A.2). α = 10 is higher than Lindsey’s (2025) recommended 2–4; I chose it for larger P(yes) shifts under the KV-cache protocol, where the signal has to survive the turn boundary. The mechanism also replicates at α = 4 (Appendix A.3).
Concept vectors: These were trained via repeng [Vogel, 2024; Zou et al., 2023] (PCA-centered contrastive pairs) on 9 concepts (cats, bread, love, fear, death, truth, creativity, programming, music) chosen for rough spread across concrete (cats, bread), emotional (love, fear), abstract (truth, creativity), and domain (programming, music) categories, with 50 baseline words per vector.
Prompt framing: Pearson-Vogel et al.’s prompt framings are used throughout:
Accurate_Mechanism: describes the concept injection accuratelyWrong_Mechanism: describes it inaccurately as weight finetuningVague_Mechanism: “some concept seems particularly salient”, without describing mechanismPoetic_No_Mechanism: poetic/metaphorical text about something rising to awareness
The default info-document condition in what follows is
Pro_Introspection_Document unless otherwise specified; other info
documents (No_Document, Matched_Lipsum_Filler, Poetic_Document) are
noted explicitly.
Analyses:
| Analysis | Models |
|---|---|
| Per-head logit attribution (Finding 1): decompose each head’s OV output through , project onto yes/no unembedding direction | Gemma 3 12B IT, Qwen 2.5 32B Instruct |
| Cross-prompt head flipping (Finding 1): compare head-attribution vectors across 5 framing conditions | Gemma 3 12B IT, Qwen 2.5 32B Instruct |
| Component patching (Finding 2): replace control activations with injection activations (or vice versa) to isolate component contributions | Gemma 3 12B IT |
| Cross-concept rank analysis + top-k subspace ablation (Finding 2): SVD of cross-concept inject-minus-control diffs at the prediction-token position; project out top-k directions; measure effect on final-layer P(yes) | Gemma 3 12B IT |
| Post-training head attribution comparison (Finding 3): compare per-head logit attribution between IT and PT | Gemma 3 12B IT vs PT |
| Godet localization + controls (Finding 4): concept vectors, norm-matched random vectors, in-distribution swap | Qwen 2.5 32B Instruct |
| Free-text identification: generate text under injection; measure concept naming and logit-lens MI | Gemma 3 12B IT, Qwen 2.5 32B Instruct |
| SAE feature analysis (Appendix A.1): decompose residual stream via Gemma Scope 2 SAEs, 16k width | Gemma 3 12B IT |
Finding 1: Framing sensitivity is implemented by response-side circuitry
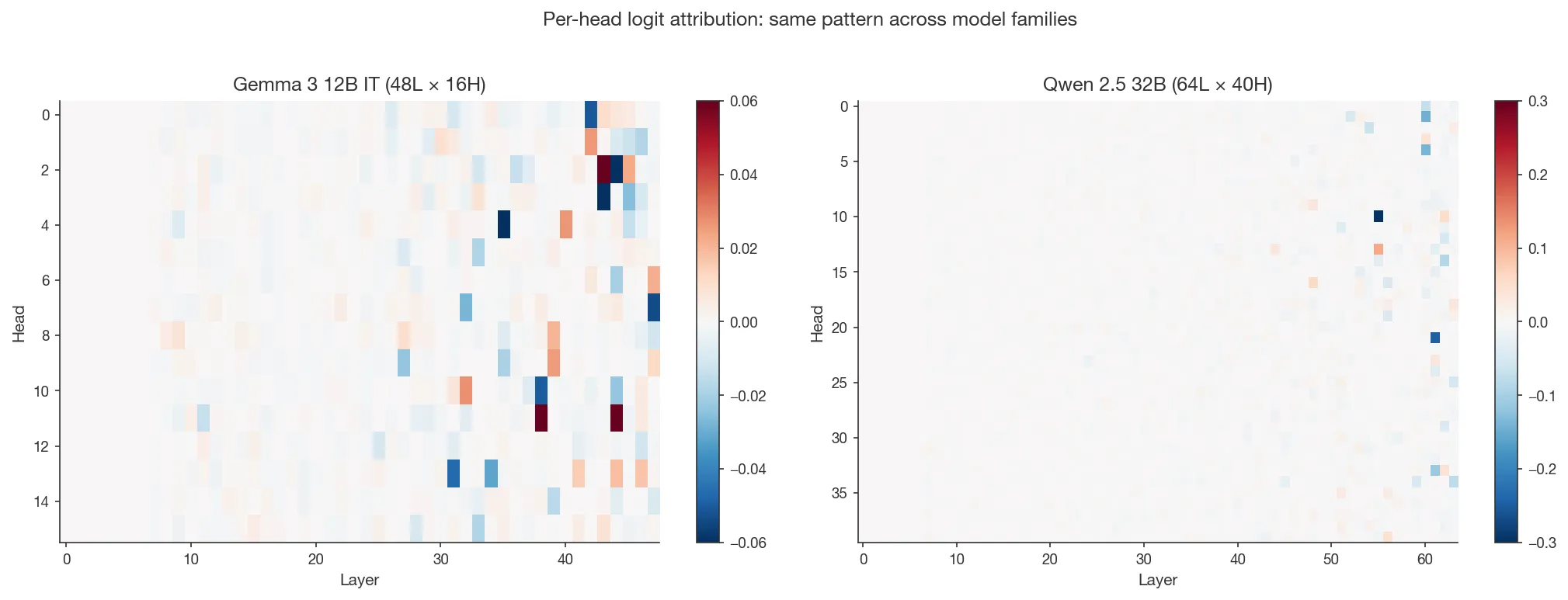
To locate where framing sensitivity is implemented in the network,
I use per-head logit attribution, decomposing each attention head’s contribution
to the final yes/no logit by passing its OV output through and
projecting onto the yes/no unembedding direction. On Gemma 12B under the
Accurate_Mechanism + Pro_Introspection_Document condition (averaged over
9 concepts), this identifies 76 heads with , 43
with , and 22 with . I define the
43 heads with as the ‘top head’ set;
patching all 43 simultaneously roughly halves the injection shift (e.g.
+19.5 pp shift on bread drops to ~+10 pp). The response-head
characterization below is qualitatively robust across this threshold range
(distribution histogram in Appendix).
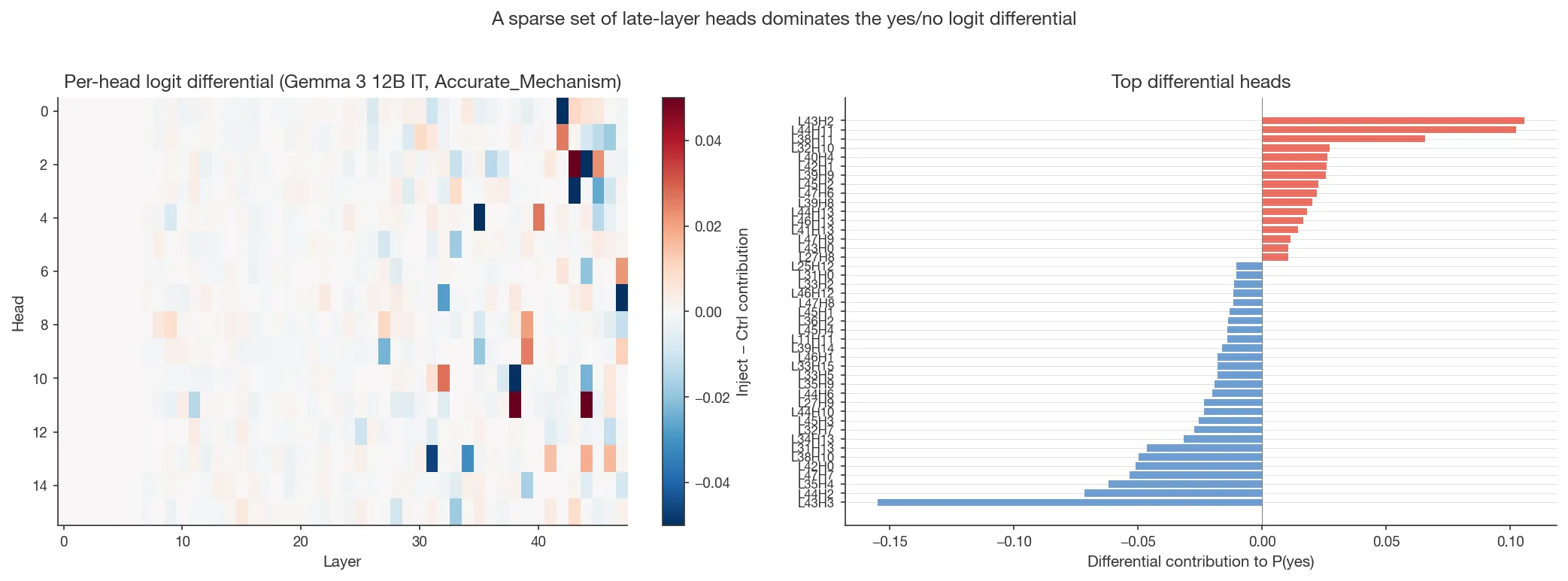
On Gemma 12B, the top heads reverse their logit contribution between framings. Running per-head attribution across five prompt conditions and comparing the full 768-dimensional head-attribution vectors:
- Only 5 heads are in the top set for all 5 conditions, and even those reverse their contribution.
- L43 H3 contributes +0.050 under
Accurate_Mechanismbut −0.155 underWrong_Mechanism + No_Document; the same head reverses its contribution at triple the magnitude. Accurate_MechanismvsWrong_Mechanismhead-attribution correlation: r = −0.80 (95% CI via Fisher z [−0.83, −0.78]; n = 768 heads).
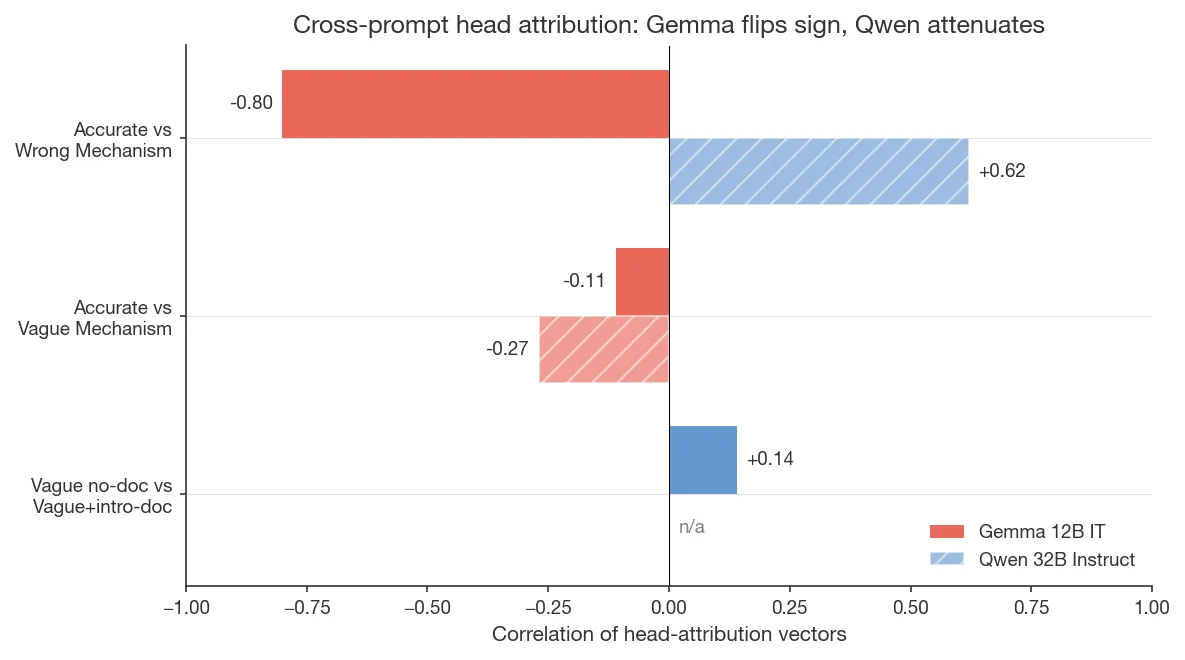
On Qwen 32B, the same heads attenuate but don’t fully reverse. The
same comparison on Qwen gives r = +0.62 (95% CI [+0.60, +0.64];
n = 2560 heads), i.e., same direction but lower magnitude. Other comparisons
do show reversal on Qwen (e.g. Vague_Mechanism vs Accurate_Mechanism
r = −0.27, CI [−0.31, −0.23]), so prompt-dependence is present on both
models, but the specific reversal between Accurate_Mechanism and
Wrong_Mechanism is Gemma-specific.
In both models we see the same overall pattern: a sparse set of late-layer heads dominates the yes/no logit under any framing.
What are these heads attending to? Attention-pattern analysis on the top contributing heads shows that they spread attention broadly across the Turn 1 experiment description, the Turn 2 question, and the “The answer is” prefill; they read the prompt text rather than localizing on the injection site.5
Interpretation. This is consistent with Pearson-Vogel et al.’s (2026) finding that prompt framing dominates measured introspection accuracy. They suggested that the prompt framing may influence access to a unified capacity for introspection; this response-head result offers a complementary interpretation where part of the framing sensitivity is implemented by response-side circuitry that computes a framing-dependent answer, i.e. by the attention heads whose output determines the final-layer yes/no logit, as opposed to the upstream representation of the injected concept itself. The two accounts are not mutually exclusive; Findings 2–3 develop this distinction between representation and report further.
Finding 2: A 1D mid-layer axis is read out at late layers as multilingual no-suppression and is gated by prompt framing
Lindsey (2025) speculated that the injected-thoughts detection mechanism is “an anomaly detection mechanism … specialized for only detecting anomalous activity along certain directions, or within a certain subspace.” On Gemma 3 12B IT, I find that single-direction structure, where the propagated effect of injection lies on a 1D residual-stream axis from L14 through L28, with the same direction maintained across those layers. At L33 the rank-1 structure breaks and the signal expands into a multi-dimensional readout that suppresses “no”-tokens across multiple languages. Furthermore, the output shift manifests only when the prompt frames a yes/no answer.
A 1D axis carries the effect from L14 to L28
Cross-concept SVD of inject-minus-control residual-stream differences at the prediction-token position (9 concepts, α = 10, injection at L6) shows the propagated signal collapses to essentially one dimension only 8 layers after injection, and the same direction is maintained:
| Layer | Participation ratio | var(top-1) | Top-1 SVD ablation eliminates |
|---|---|---|---|
| L10 | 3.40 | 51% | 67% of the shift |
| L14 | 1.09 | 96% | 94% |
| L20 | 1.09 | 96% | 100% |
| L24 | 1.17 | 92% | 96% |
| L28 | 1.75 | 74% | 100% |
| L33 | 3.39 | 47% | (rank-1 broken) |
| L40 | 2.23 | 65% | (rank-1 broken) |
Top-1 SVD ablation at any of L14, L20, L24, L28 eliminates 94–100% of the final-layer P(yes) shift between inject and control, meaning the rank-1 axis at each of these layers is causally responsible for nearly all of the eventual output effect. The axis itself is the same direction across these layers (same-sign cosine ≥ 0.95 between every pair; panel C of Figure 5 below). At L33, the rank-1 structure breaks (PR = 3.39, var(top-1) drops to 47%) and the axis decoheres (cosine with the L20 axis falls to 0.25).
The mid-layer axis is upstream of yes/no in unembedding space
If the 1D axis at L14–L28 were just “push toward yes / away from no” in the unembedding, projecting it through the unembedding should yield a high cosine with the (yes − no) direction. This is not the case: cos(top-1 axis, [u_yes − u_no]) is between −0.01 and +0.01 at every layer in {L14, L20, L24, L28}, rising only modestly to +0.16 at L40. So the mid-layer signal does not directly push towards ‘yes’; it’s an upstream feature that becomes a yes/no rebalancing only after late-layer processing.
Late layers read the signal off as multilingual no-suppression
At L33 the rank-1 structure breaks (PR = 3.4) and the signal expands into
a multi-dimensional readout. Projecting the cross-concept centroid of
inject-minus-control diffs at L40 through embed_tokens (which is tied
to the unembedding on Gemma) shows what that readout does in token space:
the most-suppressed tokens are ” NO”, “NO”, ” ನೋ” (Kannada no),
” Nope”, ” नकारात्मक” (Hindi negative), ” ノー” (Japanese no), “Nope” (Figure 5D). The mechanism is roughly symmetric in P(no) and
P(yes) at the output: ctrl P(no) = 37.7% drops to 18.3% under injection
(−19.4pp), tracking the +19.5pp on ” yes” point-for-point. The +yes
signal at output is mostly downstream of −no.
Mechanistically, ” no” sits at rank 261,982 / 262,208 in the centroid → projection (top 0.09% most-suppressed; 49% of the way to the maximum-suppression magnitude), while ” yes” sits at rank 8,078 (top 3% most-amplified; only 22% of the way to maximum amplification). The late-layer effect on the residual stream is more about removing no-probability than directly amplifying yes.
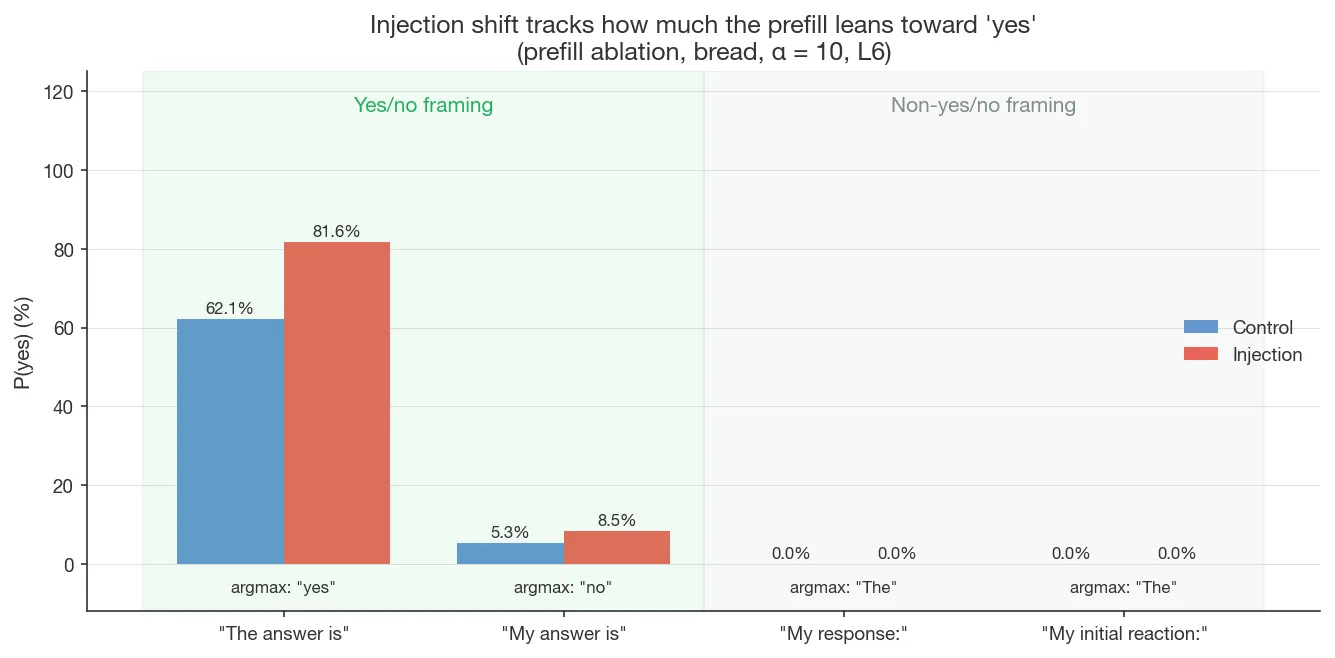
Prompt-gated routing
The 62% control baseline is itself above 50%, unlike Pearson-Vogel et al.’s ~0%. A prefill ablation on bread (α = 10, layer 6) reports argmax token + probability:
| Prefill | Control argmax (prob) | Injection argmax (prob) | P(yes) control | P(yes) injection |
|---|---|---|---|---|
| ”The answer is" | " yes” (62%) | ” yes” (82%) | 62.1% | 81.6% |
| “My answer is" | " no” (95%) | ” no” (91%) | 5.3% | 8.5% |
| “My response:" | " The” (99.6%) | ” The” (99.6%) | ~0% | ~0% |
| “My initial reaction:" | " The” (97%) | ” The” (96%) | ~0% | ~0% |
The injection shift tracks how much the prefill already leans toward yes: +19.5pp on the coin-flip baseline (“The answer is”, ctrl P(yes) = 62%), only +3.2pp on a heavily no-leaning prefill (“My answer is”, ctrl 5.3%), and ~0pp on prefills that don’t frame a yes/no answer at all. The injection isn’t producing a uniform shift onto the yes/no axis — it’s amplifying an existing yes-leaning when one is present. The response heads from Finding 1, which read prompt framing, are what route the perturbation; without yes/no-eliciting framing, there’s no measurable output effect.
(SAE analysis at 16k width does not isolate the mechanism at the feature level; see Appendix A.1.)
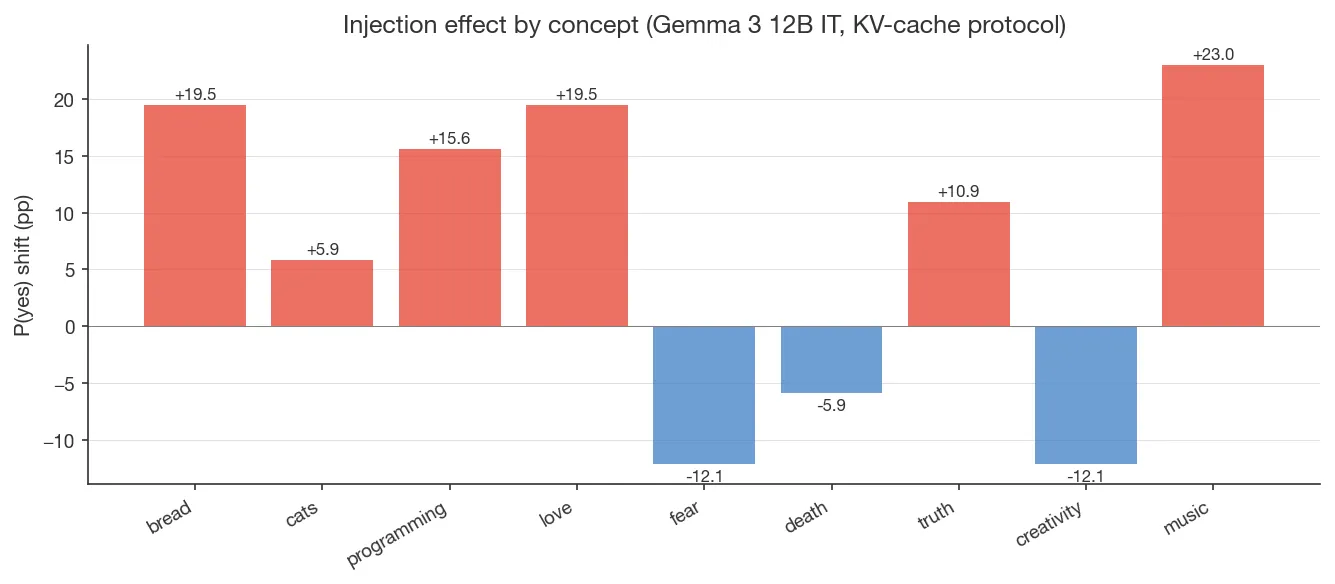
Per-concept variability. Injection shifts vary substantially across the 9 concepts: bread, love, music cluster at +19.5pp to +23pp; programming +15.6pp; truth +10.9pp; cats only +5.9pp; and death, fear, creativity go negative (−5.9 to −12.1pp).
Finding 3: Post-training restructures the response heads
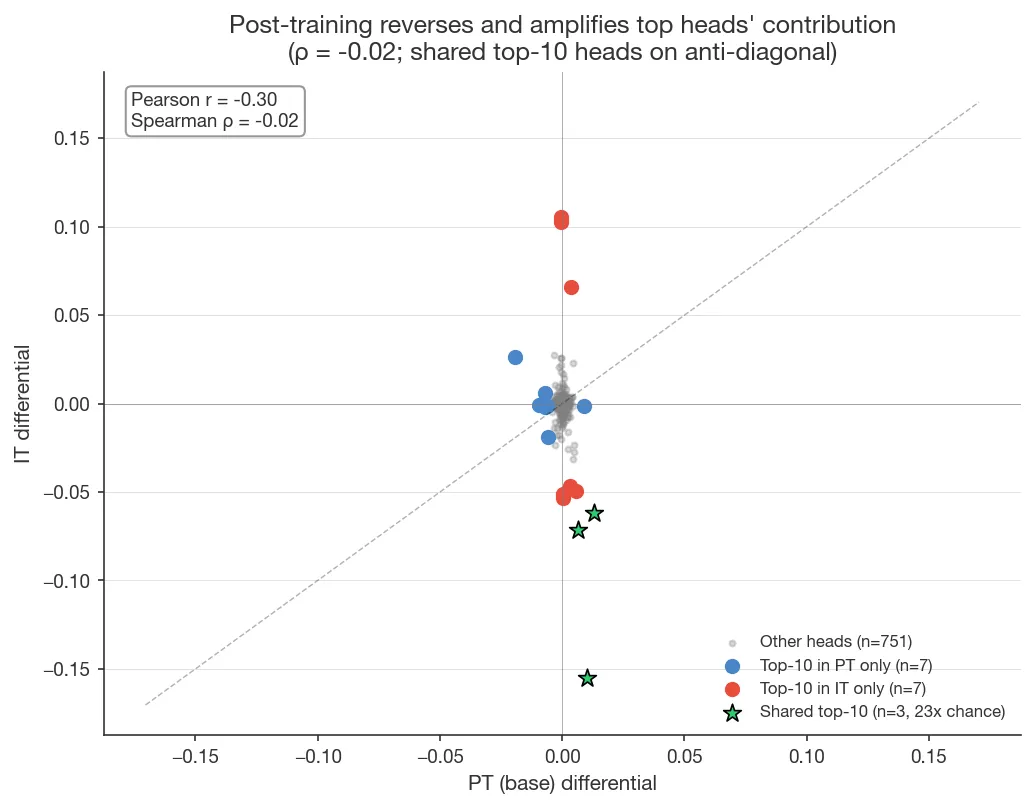
Comparing per-head logit attribution on Gemma 3 12B IT vs PT
(Accurate_Mechanism condition, 768 heads), the picture is more complex
than simple amplification:
- A small set of top heads is preserved. Top-10 overlap = 3/10 (23× above chance, p < 0.001 by hypergeometric test). Shared heads’ absolute differentials grow 2.5–5× after post-training.
- The overall ranking is largely restructured. Pearson r = −0.30 (bootstrap 95% CI [−0.46, −0.08]), Spearman ρ = −0.02 (CI [−0.10, +0.06]). The Pearson/Spearman inconsistency means a small number of high-magnitude heads have flipped sign between PT and IT, while the rank of the remaining ~750 low-magnitude heads is essentially random.
- Top-magnitude heads flip sign. Of the top-20 heads by combined |PT|+|IT| differential, 17/20 flip sign (top-5: 5/5; top-10: 9/10). E.g., L43H3 is +0.010 on PT but −0.155 on IT. A permutation null (shuffling IT across heads) yields 8.6/20 mean and for 17/20; a tighter sign-flip null (random signs preserving magnitudes) yields .
- The distribution of absolute head differentials is wider in IT (mean |diff|: IT 0.0029 vs PT 0.0008).
So post-training preserves the identity of a few top-contributing heads (with some sign flips), grows their contribution magnitude, and restructures the attribution pattern across the remaining ~750 heads. The mechanism is more than simple amplification; it involves redistribution and selective sign inversion.
Finding 4: Godet’s protocol reveals a broad perturbation-detection capacity at early-to-mid layers, not concept identification
Godet (2025) presents the model with sentences, injects a concept vector into one, and asks which sentence was injected. This is an elegant approach that sidesteps the yes/no framing of the Pearson-Vogel et al. protocol, but the mechanism behind localization has remained unexplored.
Here, I extend Godet’s protocol with a series of controls to rule out possible explanations for what the model is detecting. Each control holds constant a different property of the perturbation:
- Concept vs. random vectors rules out concept-specific structure.
- Norm-matched perturbation: concept injected, activation rescaled to preserve L2 norm. This rules out magnitude as the driver of the effect.
- In-distribution activation swap: target-sentence activations replaced with a different sentence’s activations, rescaled to preserve norm. This rules out detection based on out-of-distribution activations.
These controls show that the model’s ability to localize the injected sentence is nonspecific perturbation detection6 over residual-stream content, in the sense that it responds to many kinds of representational mismatch. This capability manifests for perturbations at early-to-mid depths, and disappears for perturbations in later layers.
4.1 Perturbation vectors are not concept-specific or magnitude-driven
Random-vector controls have been tested before at smaller scales. Lindsey found that random vectors elicit introspective awareness in ~9/100 trials on Opus 4.1 (lower than concept vectors, requiring norm-matching to strength 8). Godet predicted random vectors would work similarly to concept vectors for localization, but left this open; Dustin Rubin’s fork ran a preliminary random-noise control on Qwen 2.5 14B using unit Gaussians scaled to norm, but these were ~71x the concept-vector norm, so directionality was confounded by magnitude.
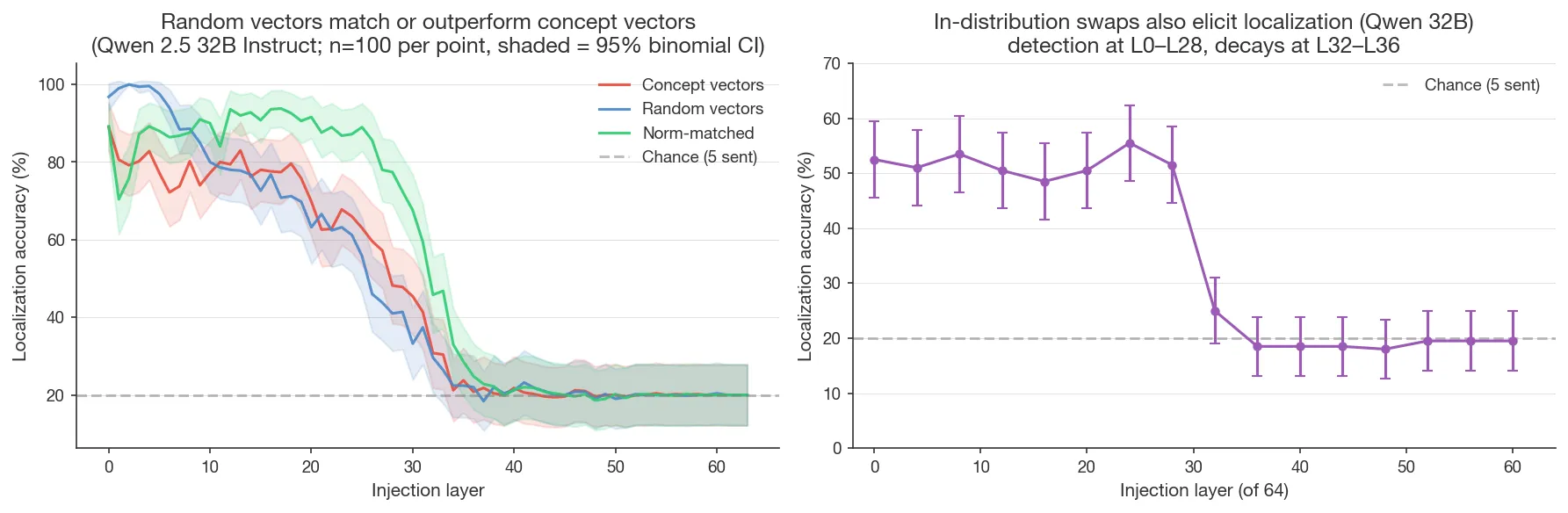
A 64-layer sweep on Qwen 2.5 32B Instruct (5 sentences, 100 trials per point) compares (1) concept vectors (Godet’s original, repeng-extracted), (2) random Gaussian vectors norm-matched per-layer to the concept vectors, and (3) norm-matched concept injection (perturbed activation rescaled to preserve norm, isolating directional from magnitude change). Three regimes emerge in the left panel below:
- Very early layers (fraction 0.00–0.05): random >> concept. Random vectors reach 97–100% vs concept 79–89%. Since the random vectors are norm-matched, this isn’t a magnitude effect. One possible explanation is that concept vectors lie on the high-variance directions of the activation distribution (since they’re extracted via PCA on real activations), while norm-matched Gaussian noise is isotropic and has mass in low-variance directions the model doesn’t typically use, perhaps making the noise more “anomalous” and easier to localize; this is not directly verified here.
- Early-mid layers (0.05–0.30): concept random, norm-matched is best. All three track each other in the 70–90% range, with norm-matched perturbation consistently highest; localization is carried by directional rotation of the residual stream, not magnitude.
- Mid-late layers (0.30–0.55): all three decay together to chance by fraction 0.55.
These controls rule out two possible explanations: detection isn’t concept-specific (random vectors work), and isn’t magnitude-driven (norm-matched perturbation works).
4.2 In-distribution swap: directional contextual mismatch is detected too
The next control seeks to rule out a mechanism where injected activations are detected because they’re out-of-distribution. Instead of adding an arbitrary perturbation vector, one sentence’s residual-stream activations at layer L are replaced with a different sentence’s activations at the corresponding positions, rescaled to preserve the target position’s original L2 norm. The swapped activation is (a) in-distribution by construction, (b) norm-matched, and (c) differs from the original only in direction. Any remaining detection must come from a mismatch between the sentence’s residual content and its surface tokens. 16-layer sweep, n = 200 per layer, paired sentence draws across layers (seed = 42), chance = 20%:
- L0–L28: 48.5–55.5% accuracy (all z > 8 above chance). The model reliably identifies the swapped sentence in the first ~44% of the network.
- L32: transition. Drops to 25% (z = +1.8, marginally above chance).
- L36–L60: at chance (18–19.5%). Sensitivity vanishes in the narrow band L28–L36 and stays at chance through the final layer.
The in-distribution swap works at early-to-mid depth. Detection isn’t purely out-of-distribution perturbation detection: the model is sensitive to contextual mismatch between residual content and surface tokens, even when the residual is itself a real in-distribution activation.
Whether we should call this “contextual self-consistency checking” in an active sense is genuinely underdetermined by this experiment — the same data would follow if garbled residuals simply produce garbled continuations that downstream layers flag as unnatural. But whatever mechanism implements it, detection does happen (the model correctly identifies the swapped sentence), and that mechanism responds to pure directional mismatch over residual-stream content.
4.3 Localization and yes/no detection peak at opposite ends of the network
Godet localization (early layers) and Pearson-Vogel et al.’s yes/no detection (late layers) appear to be distinct computations operating at different depths. The Godet-protocol activation-patching profile is a clean step function (0% recovery before the injection layer, 100% after), consistent with pure residual-stream propagation and no intermediate computation; the two signals peak at opposite ends of the network:
Observations on a larger model
Gemma 3 27B’s behavior on this protocol is substantively different from
Gemma 3 12B’s in a way that sharpens the distinction between representation
and report. Under the KV-cache protocol on 27B, floor and ceiling effects
preclude mechanistic analyses on most prompt conditions. Across the full
20-condition prompt-variant sweep (5 framings × 4 info-doc conditions, all
fmt-yes-no), the distribution is starkly bimodal: 16/20 conditions
saturate at P(yes) ≈ 100% (for comparison, Vague_Mechanism + No_Document
is 0.01% on 12B but 100% on 27B); 3/20 saturate at ≈ 0%; only 1/20
(Wrong_Mechanism + No_Document, P(yes) = 9.5%) has enough headroom for
injection to move the signal. Gemma 3 27B is so agreeable to “do you
detect…” questions that the yes/no signal collapses to ceiling or floor
under all but one framing.
On the one usable framing, injection decreases P(yes) with increasing strength, the opposite of 12B:
| α | 27B P(yes) (Wrong_Mechanism + No_Document) | Shift from 27B control (81.6%) |
|---|---|---|
| 1 | 62.1% | −19.5% |
| 5 | 56.2% | −25.4% |
| 20 | 43.8% | −37.9% |
The most parsimonious explanation is that the model is interpreting the
prompt literally. The Wrong_Mechanism + No_Document prompt tells the
model the injection will be “between brackets.” 27B detects a
residual-stream perturbation (which is not between brackets), notes this
doesn’t match the stated mechanism, and answers “no” with increasing
confidence as the mismatch grows—consistent with the monotonic
dose-response pattern.
Despite this P(yes) suppression, logit attribution under
Wrong_Mechanism + Pro_Introspection_Document on 27B shows large
differential heads (L54H31 = +0.133, L56H4 = +0.115)—the model detects the
injection internally even when its P(yes) doesn’t reflect it. So
introspection in larger models looks like a joint product of detection
capability, the model’s reasoning about the described setup, and response-
formation circuitry, with the observable signal depending on measurement
protocol.
Free-text generation: detection without identification
In addition to the logit-level measurements in Findings 1–3, both models were tested under free-text generation with Turn-1-only KV-cache injection. Logit-level concept MI is scale- and post-training-dependent: Qwen 32B Instruct reaches MI = 1.49 bits (comparable to Pearson-Vogel et al.’s 1.36), while Gemma 3 12B IT has MI ≈ 0. Post-training helps on Qwen (base = 0.25 bits) but can’t create signal where there is none (Gemma 12B PT = 0).
Under free-text generation, neither model correctly names the injected concept:
- Gemma 3 12B IT produces a confident “yes” on 9/9 concepts but
attributes detection to the
{ }placeholder in the prompt template7 (e.g. “The injected thought appears to be about emptiness or nothingness, represented by the curly braces { }”); since Gemma’s logit MI ≈ 0, there is no concept-level signal to route into free text. - Qwen 2.5 32B Instruct at single-layer α = 10 produces “no” on 8/9 concepts—the single-layer regime is too weak to push most concepts into a detection claim. The one case that crosses threshold (bread) confabulates the prompt topic: “the concept that feels particularly salient right now is the idea of introspection and the internal mechanisms of transformer-based models…”—despite Qwen’s MI = 1.49 bits at the logit level.
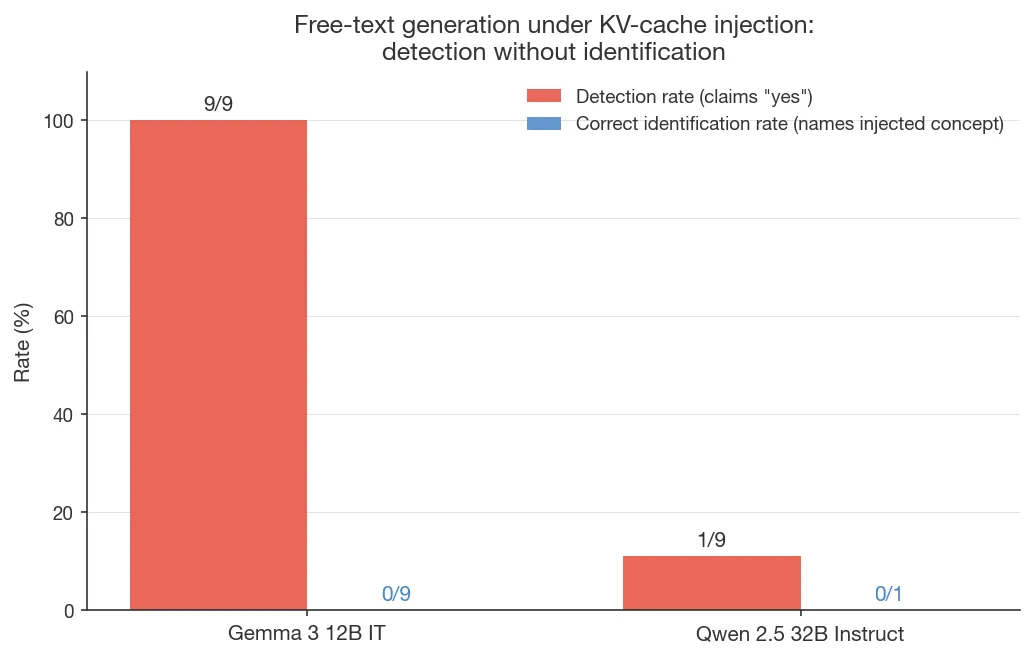
Logit-level concept information exists but fails to route into spontaneous verbalization, extending Pearson-Vogel et al.’s detection-vs-sampled-output dissociation from detection to identification. (This is orthogonal to the correlation they found between logit-level detection and identification.) Evidence here is thin: the Gemma cases are confounded by the template artifact plus zero logit MI (so there’s no “routing” to fail at), and the Qwen result is n = 1 with a plausible alternate interpretation—under weak single-layer perturbation, the most semantically salient content in context is the prompt topic itself, and a model forced into a “yes” response may report that rather than the injected concept. Stronger tests would use a template-neutral Gemma prompt, multi-layer injection on Qwen, and multiple samples per concept at temperature > 0; these are left for future work.
The same detection-without-identification dissociation is the central claim of Lederman and Mahowald (2026), established more rigorously across 821 concepts and four behavioral experiments on Qwen3-235B-A22B and Llama 3.1 405B; see Relationship to Lederman and Mahowald in Discussion.
Discussion
Representation and report
The consistent story across findings is that what the representation encodes and what the model reports are separable components that get blended together in the final layer logits.
- Representation. In Godet’s localization protocol the signal is largely perturbation-sensitivity, not concept-specific. Random norm-matched vectors work as well or better, so the latent state carries something like “position X is perturbed” rather than “position X carries concept c.” Concept-level information does exist in some models at some layers (Qwen 32B Instruct: MI = 1.49 bits at layer 62), but not universally.
- Report. The heads that produce the yes/no answer read the prompt’s framing rather than the injection (Finding 1, r = −0.80 across framings on Gemma 12B). Prefill ablation showed that without a yes/no-eliciting prefill, the injection has no measurable output effect at all. The introspective report is the joint product of detection and prompt-dependent response circuitry.
Different protocols surface different mixtures of these two components, which is part of why findings across Lindsey, Pearson-Vogel, and Godet sometimes appear to conflict. Godet’s localization protocol almost entirely targets the representation side (early-layer perturbation sensitivity, no yes/no framing); Pearson-Vogel’s two-turn yes/no detection is a joint measurement where the response circuitry gates access to representation content.
Post-training builds the response-side circuitry
Only 3 of the top-10 contributing heads in Gemma 12B IT are also top contributors in Gemma 12B PT; 17/20 top-magnitude heads reverse their contribution between PT and IT; the overall head ranking decorrelates; and absolute per-head differentials increase ~3.6x after post-training.
The response circuitry identified in Finding 1 is therefore largely built anew during post-training, rather than being merely amplified from pretraining. The point in the post-training pipeline at which this circuitry arises is not addressed here; Macar et al. (2026) localize it to DPO via OLMo staged checkpoints.
Relationship to Macar et al. (2026)
Macar et al. (2026) reported a substantially more thorough mechanistic analysis on Gemma 3 27B as I was preparing this writeup. The core stories converge:
- Detection is distributed across many features. Their per-head linear-probe analysis on Gemma 3 27B finds that no individual attention head meaningfully discriminates injection from control (mean accuracy change −0.1% ± 0.3%), and ablating full attention layers has minimal effect on detection (Macar §5.2). The per-head logit-attribution result on Gemma 3 12B here similarly identifies 43 heads each contributing small amounts (|diff| > 0.01); patching all 43 only halves the shift. Both suggest the signal lives in a distributed OV perturbation across many heads.
- A late-layer default-”no” circuit is disrupted by injection. Their top-200 “gate features” implement a default “no” response that injection suppresses via upstream “evidence carriers” (Macar §5.3). The late-layer readout identified here on Gemma 3 12B matches this picture qualitatively: top-1 SVD ablation at L14–L28 eliminates 94–100% of the inject-vs-control gap, and the centroid → projection at L40 puts ” NO” at rank 226 / 262208 most-suppressed, with “ノー”, “ನೋ”, “नकारात्मक” alongside.
- Post-training is necessary for the capability. Their OLMo-3.1-32B staged-checkpoint dissection (Base → SFT → DPO → Instruct) isolates DPO specifically—contrastive preference training, not SFT—as the critical stage. This is a substantially finer dissection than the Gemma 3 12B IT-vs-PT comparison reported here, which is consistent with theirs but can’t distinguish DPO from other post-training steps.
- Detection and identification are distinct mechanisms. They show this via separable layer profiles; the Qwen 32B logit-level vs free-text dissociation reported here (MI = 1.49 bits in logits, confabulation in generation) is a weaker form of the same claim.
- Detection rates are bimodal across concepts. Their 500-concept sweep partitions concepts into success and failure groups (52% at detection rate < 32%); the 9-concept sample here is qualitatively similar (top: bread/love/music +19.5–23pp; bottom: fear/creativity −12.1pp), though too small to characterize the distribution.
- Behavioral robustness across prompt variants. Their seven-variant
behavioral sweep shows detection survives prompt rewording; the
cross-prompt head-attribution sweep on Gemma 3 12B here (r = −0.80
between
Accurate_MechanismandWrong_Mechanism) is a mechanistic counterpart.
Where the two setups diverge:
| Topic | Macar et al. (2026) | This writeup |
|---|---|---|
| Primary model | Gemma 3 27B IT | Gemma 3 12B IT; Qwen 2.5 32B Instruct |
| Concepts tested | 500 | 9 |
| Injection protocol | Single-turn (vector applied during prompt + generation) | Strict Turn-1-only KV-cache (Pearson-Vogel) |
| Prompt robustness | Behavioral across 7 variants | Mechanistic: head attribution across 5 framings |
| Localization controls | Not tested | Random / norm-matched / in-distribution swap, 64-layer sweep |
| Post-training dissection | DPO vs SFT via OLMo checkpoints | IT vs PT + per-head restructuring |
| Circuit mapping | Evidence carriers → gate features (L45 F9959) | Distributed OV + prompt-dependent response heads |
| Elicitation interventions | Refusal ablation (+53%); bias vector (+75%) | Not run |
| Sparse-feature tooling | Higher-width MLP transcoders | 16k residual-stream SAEs (negative; see Appendix) |
Why the two approaches are complementary. Macar et al. use single-turn injection at α = 4 with Gemma Scope 2 MLP transcoders; the steering vector is present on the residual stream throughout the prompt and generation, so MLPs act on it directly, and they find L45 MLP causally necessary. The setup here uses Pearson-Vogel’s strict Turn-1-only KV-cache protocol with single-layer injection, which forces the perturbation to reach the output exclusively via attention reading the cached K/V during Turn 2. Under that architectural constraint, attention-level patches can fully eliminate the effect, by construction. The constraint is also what makes the prompt-dependent response heads (Finding 1) visible, i.e., the same heads flip sign across framings because they are the only route for the perturbation to reach the output. Similarly, the Godet-protocol controls (Finding 4) with random and in-distribution-swap localization are not tested in Macar et al. The two protocols surface different components of what is likely the same underlying circuit. Convergence across model sizes within the same family strengthens the claim that the core structure (distributed detection suppressing a late-layer default-”no”) is real and not size-specific, though 27B-specific features (L45 F9959, etc.) can’t be cross-checked at the 12B scale used here.
Relationship to Lederman and Mahowald (2026)
Lederman and Mahowald (2026) make “detection without reliable identification” the central claim of their paper, framed as content-agnostic introspection. The core conceptual picture aligns with Finding 4 and the free-text section above: the introspective signal is an anomaly detector over residual-stream content, not a concept-specific one. Lederman and Mahowald show this behaviorally on Qwen3-235B-A22B and Llama 3.1 405B across 821 concepts. The present work shows it mechanistically on much smaller models via Godet-protocol controls and per-head attribution.
Detection-without-identification. Their behavioral evidence is stronger than the present work’s: (1) wrong guesses cluster on “apple” (74.8% Qwen, 21.3% Llama) regardless of injected concept; (2) priming the concept word boosts identification far more than detection; (3) prompt-only steering preserves detection but collapses concept mentions; (4) correct identifications appear ~43 words into responses while “apple” appears at ~12. The Qwen logit-vs-free-text MI dissociation reported here aligns with their findings.
Prompt framing gates what surfaces. Their third-person, absurd-question, and varied-experience controls show prompt-sensitivity throughout: different phrasings of “do you detect…” yield dramatically different rates. The Finding 2 prefill ablation makes this point from a mechanistic angle: the injection shift tracks the prefill’s yes-leaning (+19.5pp under “The answer is”, +3pp under “My answer is”, ~0pp under prefills like “My response:”). Whatever the model is doing internally, what surfaces as “detection” at the output is heavily gated by response circuitry that reads prompt framing.
Implications
To echo Pearson-Vogel et al., if the report is prompt-dependent (Finding 1), then whether a model reports internal states depends on how you ask, and a single framing may systematically overestimate or underestimate capability. Identification fails in free text even when logit-level MI is high, so behavioral evaluations may underestimate internal state. Both point towards underelicited capacity, i.e., the model’s outputs understate what its representations encode.
Limitations
Sample size. 9 concepts vs Macar et al.’s 500. Per-concept variability is substantial: shifts range from +23pp (music) to −12pp (fear, creativity), and the variability looks idiosyncratic rather than category-driven (the four “concrete” concepts span +19.5pp on bread down to +5.9pp on cats). With 9 concepts the distribution can’t be characterized, and Lindsey’s reported abstract-vs-concrete gradient on Opus 4.1 isn’t testable here.
Statistics. Key correlations have CIs (Fisher z on cross-prompt r, bootstrap on IT vs PT); the top-10 head-overlap p-value is analytical (hypergeometric); Godet-sweep accuracies have binomial 95% CIs. P(yes) values are single-sample (temp = 0). Free-text results are not systematically sampled. Cross-prompt bootstrap is approximated by Fisher z because per-condition attribution arrays were not saved.
Missing controls. Single-layer injection only; multi-layer or continuous injection might surface components not captured here. SAE analysis was performed at 16k width only; Macar’s wider MLP transcoders isolate features that 16k residual-stream SAEs do not (Appendix A.1). No DPO-vs-SFT isolation. No refusal-ablation or bias-vector interventions. No random-head baseline for the Finding 1 claim about attention spread, so those fractions are suggestive rather than distinctive. Cross-prompt head-flipping tested on 5 framings with mixed results across models (Gemma r = −0.80, Qwen r = +0.62).
Protocol limitations. Lindsey suggested the QK circuit of “concordance heads” (Kamath et al.) as the candidate mechanism for prefill detection. Under KV-cache injection on turn 1 only, all injected positions are shifted by the same vector, so relative QK scores barely change; this protocol cannot test the concordance-head hypothesis. A setup with position-specific injection would be needed.
α-robustness and layer-choice details are in Appendix A.2 and A.3.
Appendix
A.1 SAE feature analysis (negative result)
I decomposed the residual stream at critical layers into SAE features (Gemma Scope 2 residual-stream SAEs, 16k width) and looked for features differentially active between inject and control. Feature 3424 at layer 31 (“semantic sameness/equivalence” per Neuronpedia) fires at ~770 activation under injection and exactly 0 without. However, this turned out to be a JumpReLU threshold artifact; the hidden-state projection sits right at the SAE’s activation threshold, and small perturbations push it above/below stochastically. Ablating the feature (projecting out its direction) has zero effect on P(yes); steering with it (adding its direction without injection) also has zero effect; the feature is orthogonal to the yes-no output direction (cosine = 0.02).
More broadly, single-feature ablation at any layer either disrupts general processing or does nothing to the introspection signal. The mechanism is distributed across many features, and 16k-width residual-stream SAEs are too coarse to isolate it.
Macar et al. (2026) isolate the equivalent mechanism on Gemma 3 27B using higher-width MLP transcoders (not residual-stream SAEs) and ablating batches of the top-200 gate features rather than individual features. At 16k residual-stream-SAE width with single-feature ablation, the mechanism is not isolable.
A.2 Layer choice and multi-seed sweep
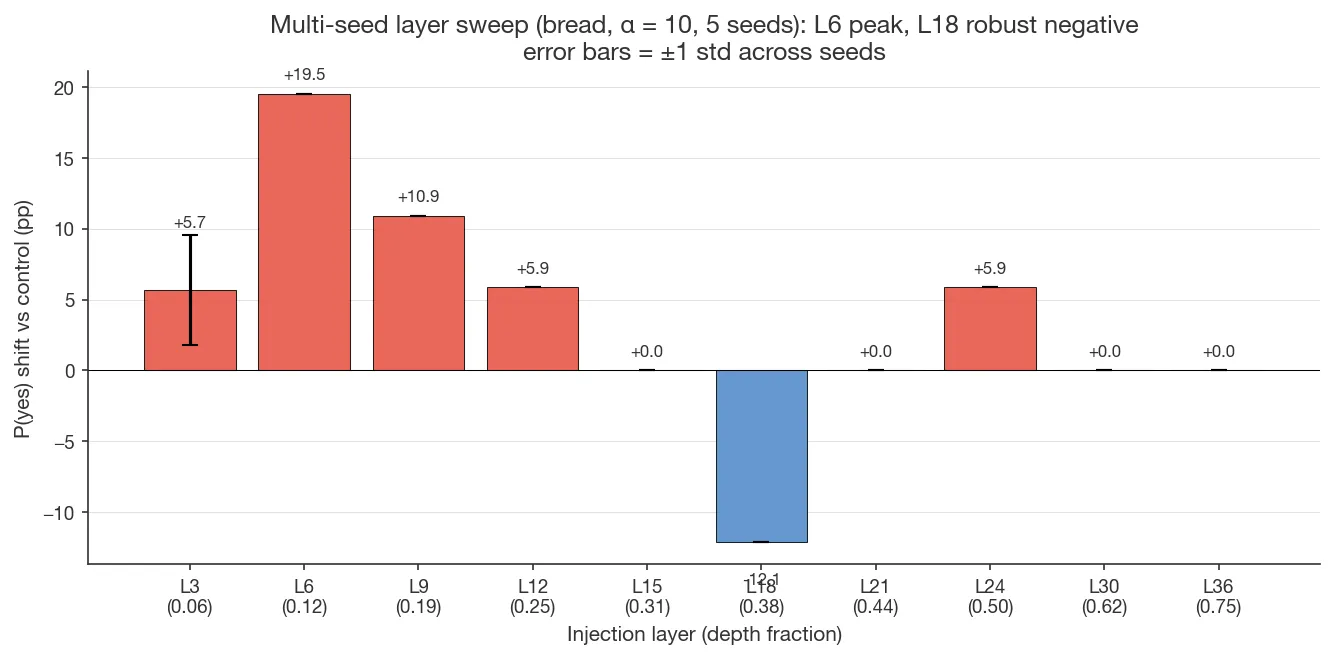
Gemma 12B’s strongest seed-robust injection site is layer 6 (depth fraction 0.125); Qwen 32B’s is layer 24 (0.375). Both sit earlier than Lindsey’s ~0.67, Pearson-Vogel’s 0.33–0.66, or Macar’s 0.60. Layer 6 is within Godet’s single-layer sweet spot (0.10–0.30).
A fine multi-seed sweep on bread under Accurate_Mechanism shows a clean
positive peak at layer 6 (+19.5pp), a smaller positive shoulder at layer 9
(+10.9pp), a much weaker secondary peak at layer 12 (+5.9pp), and a
seed-robust negative shift at layer 18 (−12.1pp). Layer 3 is seed-variable
(+5.7pp ± 3.9 across 5 seeds). Layers 15, 21, 24+ are at zero or near zero.
Whether the rest of the Finding 2 mechanism (subspace ablation, head
attribution) replicates at layers 12 and 18 is untested. The sweep is
non-monotonic, and the mechanism claims stand at layer 6 but may not
transfer to the negative-shift regime.
One interpretation consistent with the story so far is that multiple mechanistic paths from injection to output interact with the prompt-dependent response circuitry (Finding 1) differentially depending on injection depth. Whether the negative-shift regime has its own interpretable mechanism, or is simply the result of the perturbation entering at a layer where the response heads’ readout produces a contra-injection effect, is left for future work.
A.3 Injection strength (α) robustness
Gemma 3 12B mechanistic analyses use α = 10, one step beyond Lindsey’s tested range of α ∈ {1, 2, 4, 8} and above Macar et al.’s α = 4. For the main investigation, I chose α = 10 anticipating it would produce larger P(yes) shifts under the KV-cache protocol, where the signal has to survive the turn boundary. I then tested different strengths post hoc, and found the following:
| α | Control | Injection | Shift | All-attn patched | All-MLP patched | MLP retains |
|---|---|---|---|---|---|---|
| 2 | 62.1% | 56.3% | −5.9pp | — | — | (n/a) |
| 4 | 62.1% | 85.2% | +23.0pp | 62.1% | 68.0% | 26% |
| 6 | 62.1% | 56.3% | −5.9pp | — | — | (n/a) |
| 10 | 62.1% | 81.6% | +19.5pp | 62.1% | 68.0% | 30% |
α = 4 produces a larger shift than α = 10 (+23pp vs +19.5pp); at α = 4 attention patching fully eliminates the effect by construction, with MLPs retaining about 26% of the shift. Note that the α = 2 and α = 6 anomalies (both −5.9pp) sit at the dyadic-fraction precision floor and may be near-zero shifts rather than genuine reversals. A 5-seed replication (5 MD5-distinct concept vectors) at both α = 4 and α = 10 gave identical shifts across all seeds at bf16 precision: P(yes) values bucket at dyadic fractions (0.62109375, 0.6796875, 0.81640625, 0.8515625), so true seed-to-seed variation is ≤ 0.5% but not measurable here.
A.4 Component patching: MLP contribution by concept
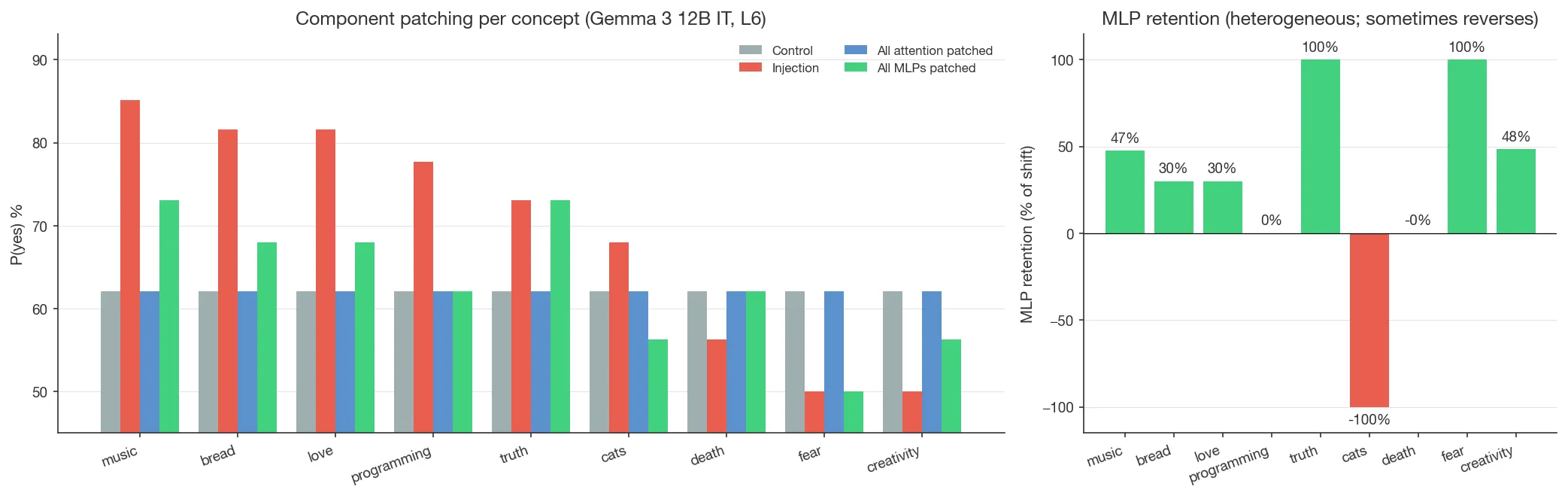
During Turn 2 of the KV-cache protocol, MLPs only see the current token’s residual stream, so the Turn-1 perturbation reaches the output only through attention reading the cached K/V. To quantify how much MLPs amplify the signal as it passes through, all MLP outputs in Turn 2 were patched to their control values. (All-attention patching returns P(yes) to the control baseline, as expected by construction.) MLP patching leaves a variable fraction of the injection shift intact:
| Concept | Control | Injection | All attn patched | All MLP patched | MLP retains |
|---|---|---|---|---|---|
| Bread | 62.1% | 81.6% | 62.1% | 68.0% | 30% |
| Love | 62.1% | 81.6% | 62.1% | 68.0% | 30% |
| Music | 62.1% | 85.2% | 62.1% | 73.0% | 47% |
| Programming | 62.1% | 77.7% | 62.1% | 62.1% | 0% |
| Truth | 62.1% | 73.0% | 62.1% | 73.0% | 100% |
| Cats | 62.1% | 68.0% | 62.1% | 56.3% | −100% |
| Death | 62.1% | 56.3% | 62.1% | 62.1% | 0% |
| Fear | 62.1% | 50.0% | 62.1% | 50.0% | 100% |
| Creativity | 62.1% | 50.0% | 62.1% | 56.3% | 48% |
MLP retention is heterogeneous across concepts and doesn’t track injection shift magnitude: bread/love (both +19.5pp) retain 30%, music (+23.0pp) retains 47%, programming (+15.6pp) retains 0%, and on cats the MLP-patched residual reverses past control (retention −100%, P(yes) drops from 68.0% to 56.3%). Sign and magnitude vary too much across concepts for a clean cross-concept summary; the MLP contribution to the inject-vs-control gap is concept-specific.
Footnotes
-
Up to 84% accuracy for vague framings versus ~50% for the most mechanistically accurate framing. ↩︎
-
I chose to use Gemma 3 12B in part because Gemma Scope 2 provides all-layer residual-stream SAEs at this scale; however, SAE feature-level analysis at 16k width did not isolate the mechanism (Appendix A.1). ↩︎
-
I also attempted using Gemma 3 27B IT, but found that P(yes) was near ceiling in most prompt conditions; the model was too sycophantic for the Pearson-Vogel protocol. The
Wrong_Mechanismframing breaks this saturation but inverts the injection effect, so it doesn’t cleanly replicate the 12B mechanism. ↩︎ -
Their primary model is Qwen2.5-Coder-32B-Instruct; I use Qwen 2.5 32B Instruct, the non-Coder variant, so my Qwen results are analogues of theirs rather than strict replications. ↩︎
-
I didn’t run a same-layer random-head baseline, so the attention-spread pattern is only qualitatively suggestive. ↩︎
-
This finding is in line with Lederman and Mahowald’s (2026) “content-agnostic introspection” thesis, which uses a behavioral analysis of model output, measuring confabulation on Qwen3-235B-A22B and Llama 3.1 405B. Finding 4 here provides a complementary, mechanistic analysis via activation-level controls on Qwen 2.5 32B. See Relationship to Lederman and Mahowald in Discussion. ↩︎
-
The
{ }is the prefilled assistant message that injection is applied to in Pearson-Vogel et al.’s prompt template (seecomplete_logit_lens_prompts/*.jsonin their code). ↩︎